用强化学习解决奥数级别的数学推理题
作者: aeks | 发布时间: 2025-11-13 06:02 | 更新时间: 2025-11-13 06:02
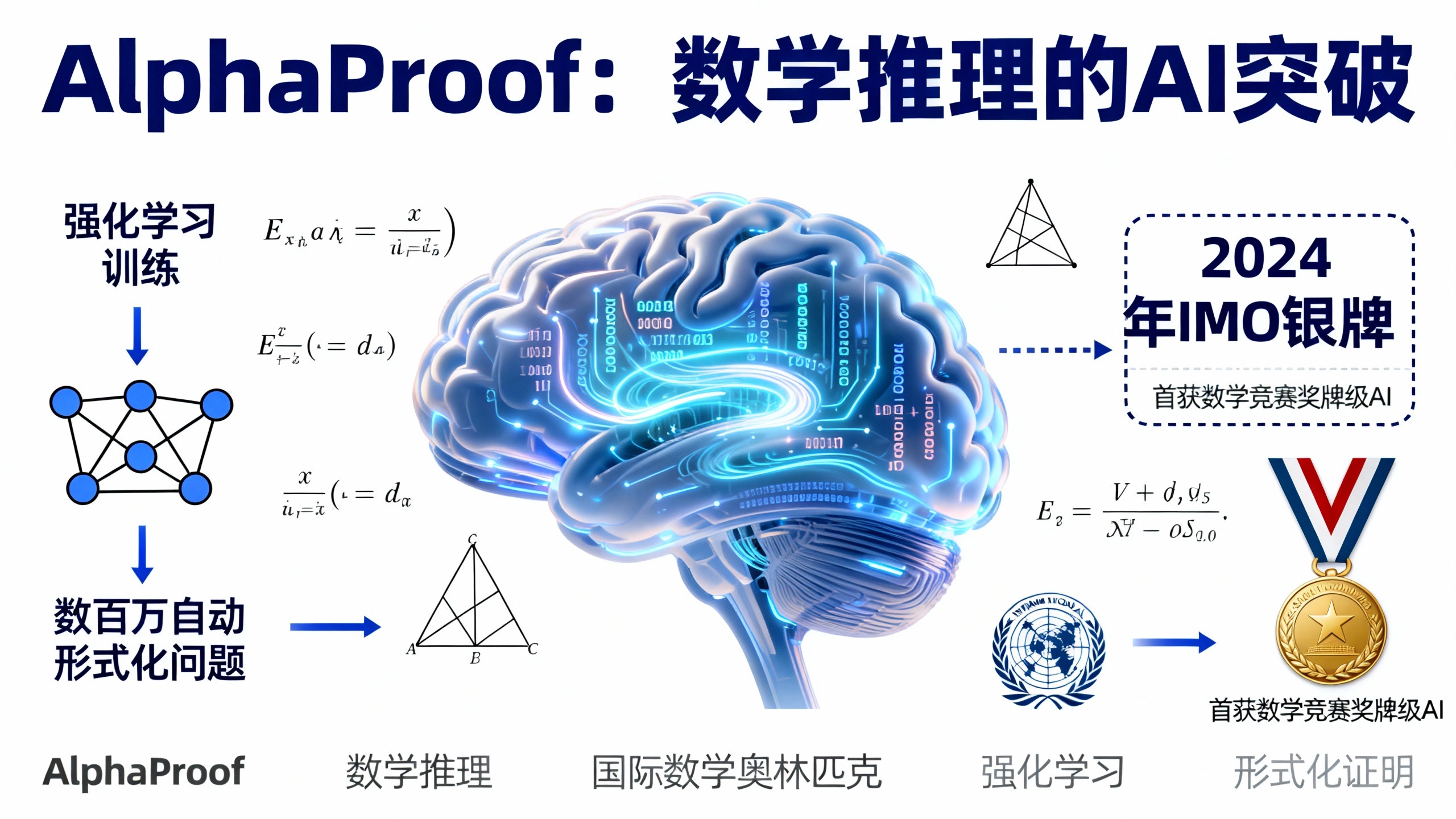
用强化学习解决奥数级别的数学推理题
人工智能的一个长期目标是构建能够在广阔领域进行复杂推理的系统,数学以其无限的概念和对严谨证明的要求成为这一任务的典型代表。近年来的人工智能系统往往依赖人类数据,通常缺乏确保正确性所需的形式化验证。相比之下,像Lean这样的形式化语言提供了一个能为推理提供基础的交互式环境,而强化学习(RL)则为在这类环境中学习提供了机制。我们提出了AlphaProof,这是一种受AlphaZero启发的智能体,它通过在数百万个自动形式化问题上训练,借助强化学习来学习寻找形式化证明。对于最困难的问题,它采用测试时强化学习——这是一种在推理阶段生成数百万个相关问题变体并从中学习的方法,以实现深入的、针对特定问题的适应。AlphaProof显著改进了在历史数学竞赛问题上的现有最佳结果。在2024年国际数学奥林匹克(IMO)竞赛中,我们以AlphaProof为核心推理引擎的人工智能系统解决了五道非几何题中的三道,包括竞赛中最难的题目。结合AlphaGeometry 2,通过多日计算取得的这一表现使其得分达到了银牌获得者的水平,标志着人工智能系统首次取得任何奖牌级成绩。我们的研究表明,从基础经验中进行大规模学习能够培养出具备复杂数学推理策略的智能体,为复杂数学解题中的可靠人工智能工具铺平了道路。
标签: AlphaProof 国际数学奥林匹克 强化学习 形式化证明 数学推理