通用标尺:让AI评估更透明、更靠谱
作者: aeks | 发布时间: 2026-04-02 06:04 | 更新时间: 2026-04-02 06:04
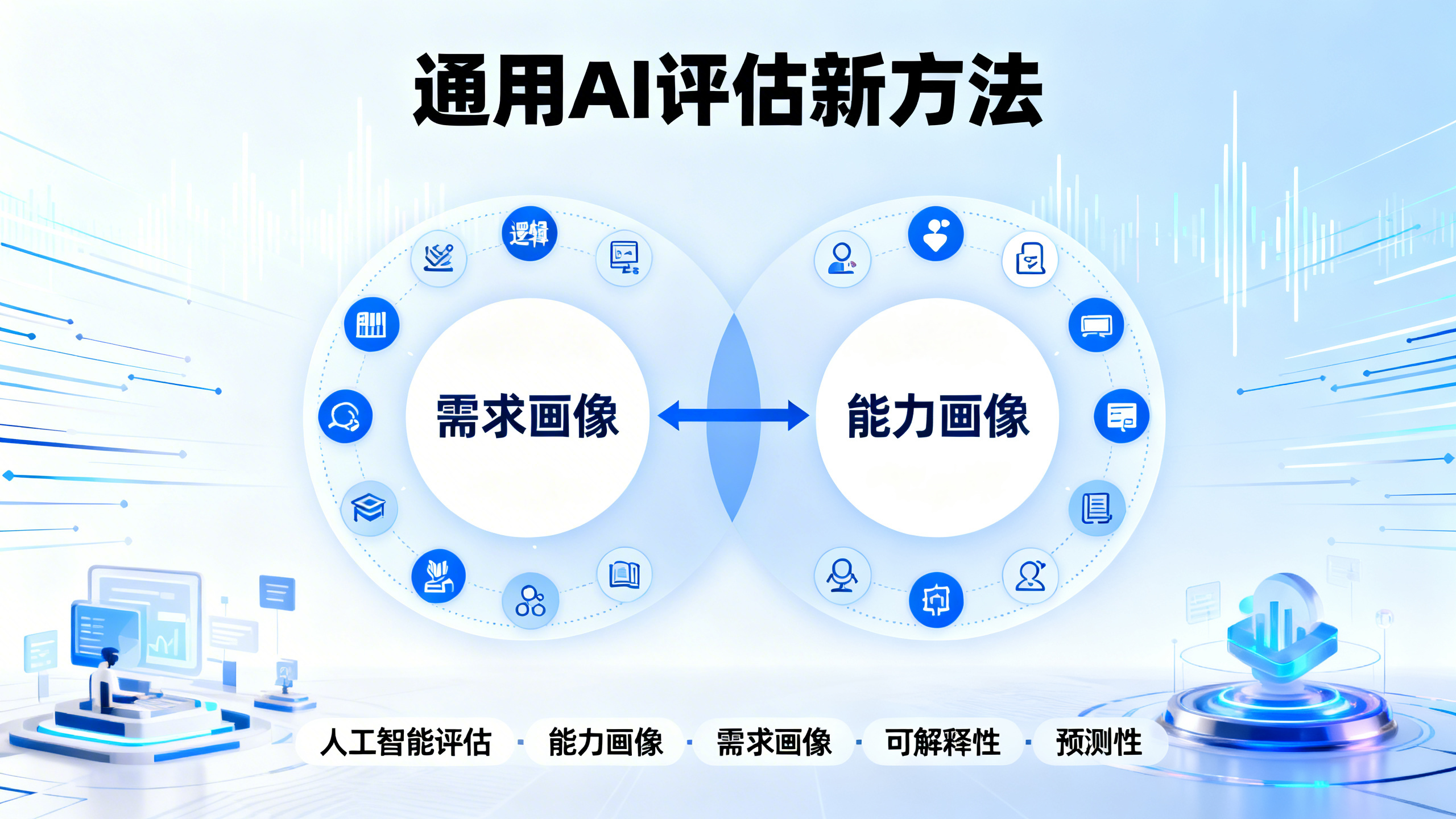
通用标尺:让AI评估更透明、更靠谱
当前主流AI评测方法存在明显局限:依赖单一基准测试的平均准确率,难以解释AI失败原因,也无法可靠预测其在新任务上的表现。本文提出的通用评估框架,核心是构建一套基于自然语言任务的18个通用能力量表(如言语理解、逻辑推理、自然科学知识等),每个量表采用0–5+级量化标注(DeLeAn量表)。研究团队用这套量表对20个主流基准中的16,108个测试题进行自动化标注,形成ADeLe评测电池。通过对题目的标注,可生成‘需求画像’——揭示每个基准实际测量的能力维度及其强度;通过对大语言模型(LLM)在这些题目上的表现建模,可生成‘能力画像’——刻画模型在各维度上的真实能力水平(非相对分数,而是绝对能力值)。例如,DeepSeek-R1-Distilled-Qwen-14B模型在定量推理、逻辑推理、归纳推理方面能力值分别为4.5、4.3、4.2;而GSM8K题目在这三项的需求值仅为2、1、0,因此可预判其高成功率;OlymMATH-Hard题目需求值则高达4–5,故预测表现较差。该方法不仅能解释看似矛盾的结果(如同一模型在不同‘数学推理’基准上准确率差异巨大),还能稳健预测未见过的新任务表现,效果远超基于嵌入向量或微调模型的传统预测器。此外,该框架具备强可扩展性:量表本身不依赖特定模型或基准,未来可轻松加入新能力维度(如安全性、公平性),并支持自动标注、模型路由、安全预警、红队测试等实际应用,为构建可信赖、可解释、可预测的AI评估科学奠定基础。