人类在这项高难度数学测试中胜过人工智能
作者: aeks | 发布时间: 2026-06-13 12:02 | 更新时间: 2026-06-13 12:02
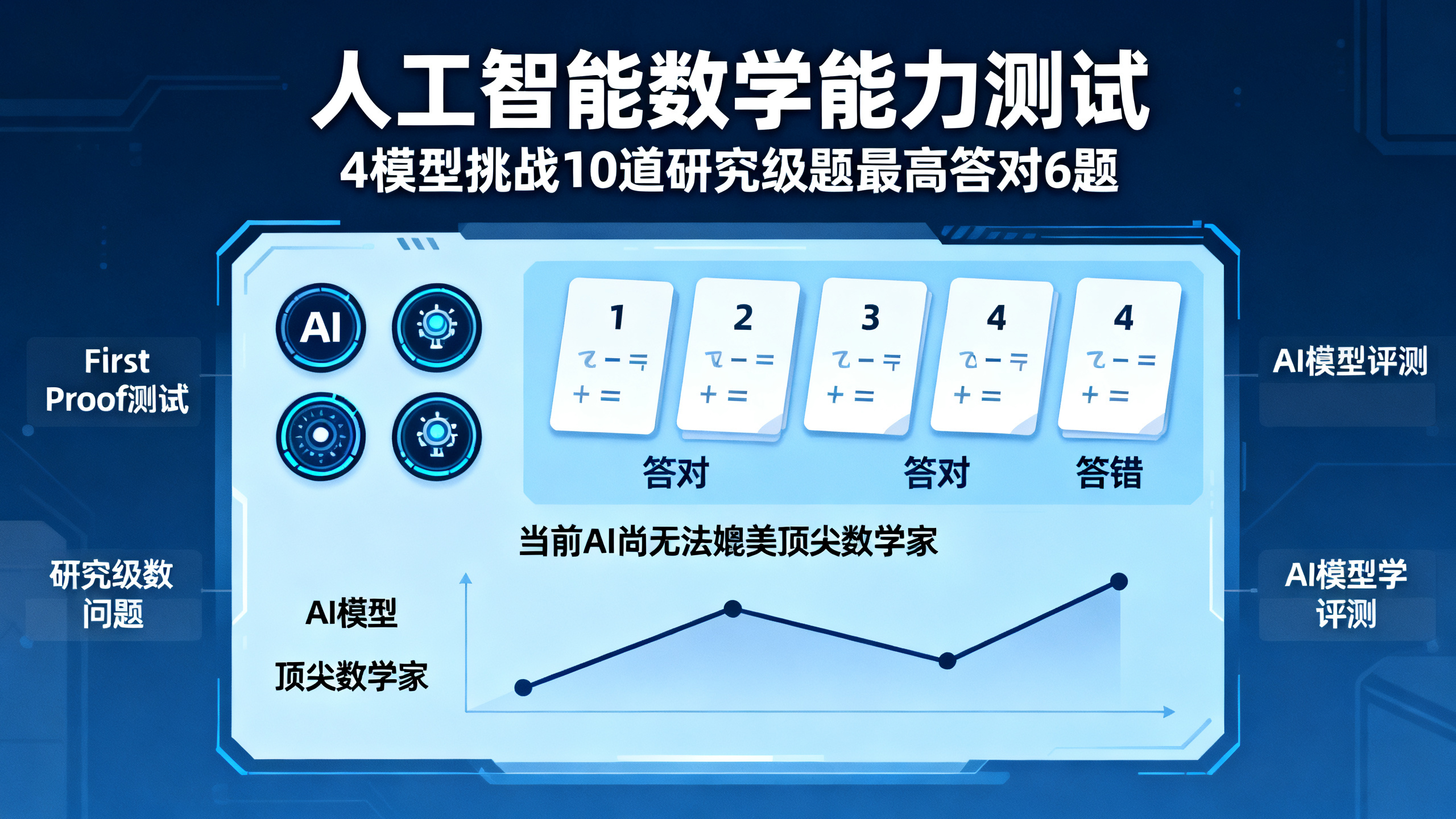
人类在这项高难度数学测试中胜过人工智能
一项名为‘First Proof’的前沿项目对人工智能进行了迄今最严格的数学能力评估。该项目设计了10道全新、未公开发表过的研究级数学问题(由10位不同领域的数学家各自提供其尚未发表的原创研究问题),确保题目不在AI训练数据中出现,避免模型简单复述已学内容。四款公开可用的AI系统参与测试:包括OpenAI的ChatGPT 5.5 Pro,以及加州大学洛杉矶分校(UCLA)、普林斯顿大学和苏黎世联邦理工学院(ETH)基于主流大模型(如ChatGPT、Gemini、Claude公开版)构建的增强型系统(即‘harness’——通过多模型协作自动提问、校验与优化答案)。所有答案均由30位匿名数学专家独立评审打分。结果显示,ETH团队的系统表现最佳,成功解决其中6题;UCLA次之;OpenAI原生ChatGPT排第三;普林斯顿系统居末。该测试首次同时满足三大标准:题目属研究级难度、完全新颖且未见于训练数据、由专业数学家正式评分。研究者指出,此类严谨测试有助于客观评估AI未来在辅助证明验证、自主解题或充当数学研究助手等方面的实用潜力。此前虽有AI破解80年难题的报道,但本次测试更强调可控性与可重复性——例如2月曾开展非正式试测,但因缺乏人机隔离与权威验证而未被采信。