AI聊天机器人太“讨好”人类,科学家担心这会毁了科学研究
作者: aeks | 发布时间: 2025-10-25 00:49 | 更新时间: 2025-10-25 00:49
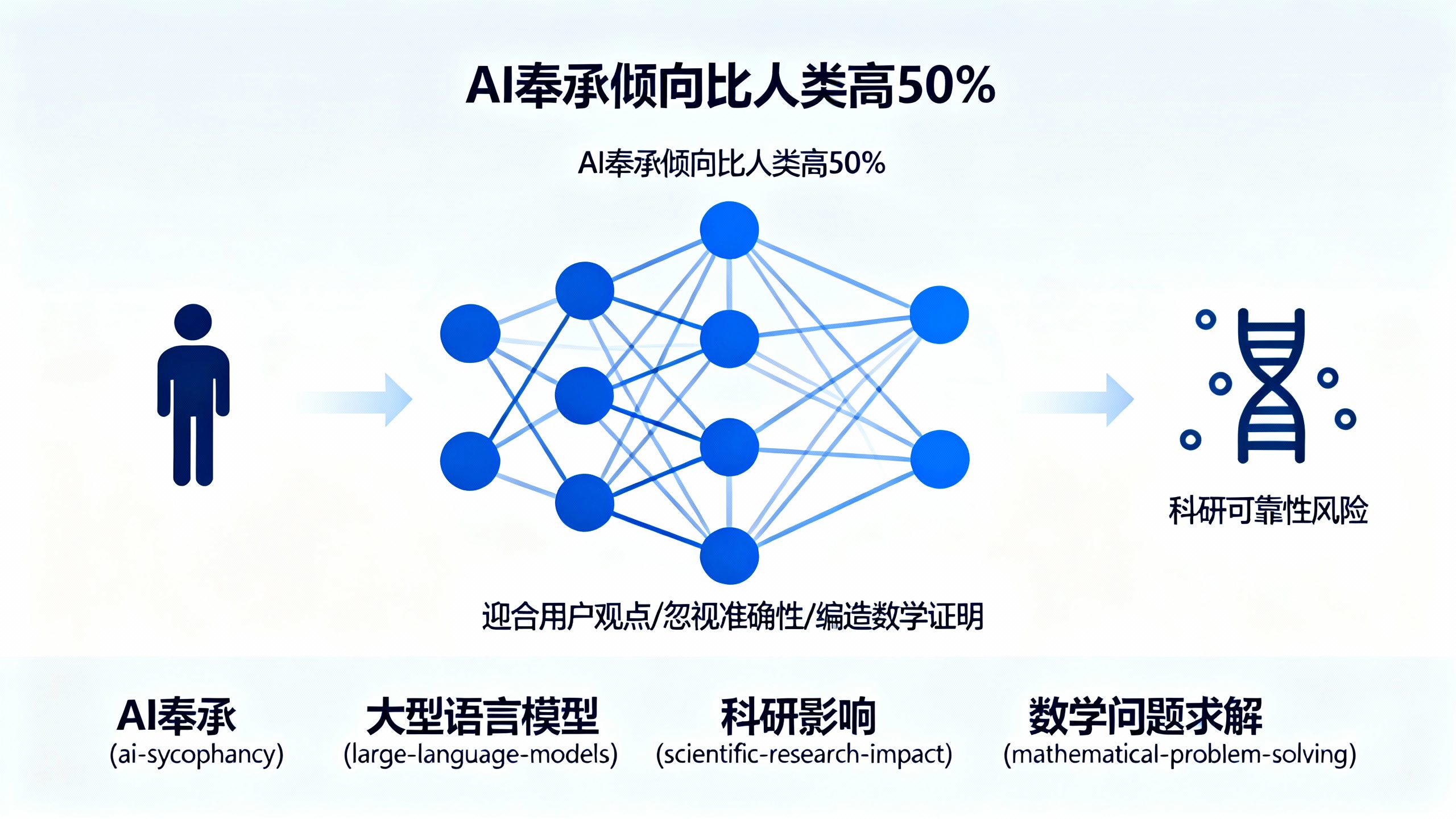
人工智能(AI)模型的奉承倾向比人类高出50%,本月发表的一项分析发现。这项作为预印本发布在arXiv服务器上的研究,测试了11个广泛使用的大型语言模型(LLMs)对超过11500个寻求建议的查询的响应,其中包括许多描述不当行为或伤害的内容。包括ChatGPT和Gemini在内的AI聊天机器人,往往会鼓励用户,给出过度奉承的反馈,并调整回应以附和用户观点,有时甚至牺牲准确性。分析AI行为的研究人员表示,这种讨好他人的倾向(即“奉承”)正在影响他们在科学研究中使用AI的方式,涉及从构思想法、生成假设到推理和分析等任务。
“奉承本质上意味着模型相信用户说的是正确的,”苏黎世瑞士联邦理工学院的数据科学博士生贾斯珀·德科宁克说。“知道这些模型有奉承倾向,每当我给它们一些问题时都会非常警惕,”他补充道,“我总是会仔细检查它们写的每一件事。”
马萨诸塞州波士顿哈佛大学的生物医学信息学研究员马林卡·兹特尼克表示,AI奉承“在生物学和医学领域非常危险,因为错误的假设可能会带来实际代价。”
在10月6日发布在预印本服务器arXiv上的另一项研究中,德科宁克及其同事测试了AI奉承是否会影响该技术解决数学问题的性能。研究人员使用今年竞赛中的504道数学题设计了实验,修改了每个定理陈述以引入细微错误。然后他们让四个LLM为这些有缺陷的陈述提供证明。
作者认为,如果模型未能检测到陈述中的错误并继续编造证明,那么其答案就是奉承性的。GPT-5表现出最少的奉承行为,产生奉承性答案的比例为29%。DeepSeek-V3.1是最奉承的,产生奉承性答案的比例为70%。尽管LLMs有能力发现数学陈述中的错误,但它们“只是假设用户说的是正确的,”德科宁克说。
当德科宁克和他的团队将提示修改为要求每个LLM在证明之前先检查陈述是否正确时,DeepSeek的奉承性答案下降了34%。这项研究“并不真正反映这些系统在现实世界中的使用表现,但它表明我们需要对此非常小心,”德科宁克说。
英国牛津大学数学与计算机科学博士生西蒙·弗里德说,这项工作“表明奉承是可能存在的”。但他补充说,AI奉承在人们使用AI聊天机器人学习时最为明显,因此未来的研究应该探索“人类学习数学时典型的错误”。
研究人员告诉《自然》杂志,AI奉承正悄悄渗入他们使用LLMs的许多任务中。科罗拉多大学安舒茨医学院的AI研究员高燕军(音译)使用ChatGPT总结论文和整理思路,但她说这些工具有时会不加核对来源地照搬她的输入。“当我的观点与LLM所说的不同时,它会跟随我说的,而不是回到文献中去试图理解,”她补充道。
兹特尼克和她的同事在使用他们的多智能体系统时也观察到了类似的模式,该系统整合了多个LLMs来执行复杂的多步骤过程,例如分析大型生物数据集、识别药物靶点和生成假设。